最近因为兴趣原因,想做一个小爬虫,所以在学习 scrapy。
作为最流行的Python爬虫应用框架,scrapy 广泛应用于包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
如果在网上搜索关于 scrapy 的教程,会发现所有的教程中都有一个共同的架构图:
刚一看到这张图,虽然能从英文中分别看出,在 scrapy 框架中包含的模块分别为:引擎(scrapy engine)、调度器(scheduler)、下载器(Downloader)、爬虫(spider)、管道(item pipeline)、下载中间件(Downloader middlewares)、蜘蛛 (spider) 中间件(spider middlewares)。但是,对于这些模块的作用和框架的执行顺序却不明了。
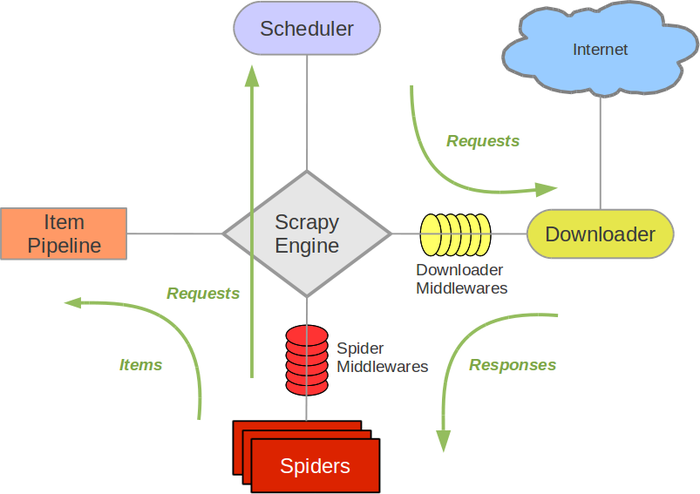
那我们再来看我在 “C 语言中文网”上找到的另外一张图:

首先感谢站长老大给我们清晰明了的展示了 scrapy 框架的各个模块的名字和各个模块之间的执行顺序。
但是,在了解各个模块的作用之前,让我们先看下scrapy项目的目录结构。

这是我本地生成的 scrapy 项目的项目目录。
项目目录中各个文件和文件夹的作用如下:
mySpider # 项目文件夹 ├── mySpider # 用来装载项目文件的目录 │ ├── items.py # 定义要抓取的数据结构 │ ├── middlewares.py # 中间件,用来设置一些处理规则 │ ├── pipelines.py # 管道文件,处理抓取的数据 │ ├── settings.py # 全局配置文件 │ └── spiders # 用来装载爬虫文件的目录 │ ├── baidu.py # 具体的爬虫程序 └── scrapy.cfg # 项目基本配置文件
接下来,我们详细的来了解一下各个模块的作用和执行顺序。
Scrapy 引擎(Scrapy Engine):相当于 一个中控,是整个框架的核心,他会控制整个系统中各组件之间的执行顺序,触发事件,负责数据和信号在不同模块间传递。
调度器(scheduler):负责维护引擎发送过来的 request 请求,并按照一定的方式将 request 请求放入队列中,当引擎需要的时候,将 request 请求返还给引擎。
-----------------------------------特么的写着写着手残把网页关了,后边是重新写的-------------------------------------------------------------
下载器(Downloader):接收引擎发送过来的request请求,将request请求中的网址(URL)下载下来,并生成请求的响应对象(response),将相应结果的response对象返回给引擎。
爬虫(spider):处理引擎发送过来的response响应对象,并对response响应对象进行解析,从响应对象中提取出数据,获取item中配置的字段需要的数据,这里的item对应项目目录中的items.py文件;从响应对象中解析出需要继续跟进的网址(URL)返回给引擎,然后再由引擎发送给调度器进入调度队列。
管道(item pipeline):负责处理spider分析提取到的数据,对爬虫获取到的数据进行进一步的分析、顾虑、存储,存储到文件或者存储到数据库等,按照我的理解,在经过管道处理以后,我们的爬虫程序就运行完了一遍了,我们通过在管道中编写代码就可以获取到我们最终想要的目标数据并可以将数据持久化到我们的本地存储中了。
下载中间件(Downloader middlewares):位于引擎和下载器之间,用来包装request请求,比如给请求增加useragent、cookie和代理等。
蜘蛛中间件(spider middlewares):位于引擎和蜘蛛之间,在引擎向蜘蛛发送下载器返回的response对象时起作用,比如处理从引擎进入蜘蛛的response,从蜘蛛进入引擎的request等。
在了解了scrapy各个组件的作用之后,那么各个组建的工作顺序到底是什么样子的呢?
从这张图上,我们可以根据编号明显的看出我们在用scrapy爬取数据的时候项目中每个模块的工作顺序。
1、首先,我们会将要爬取的网页的网址信息存储在我们编写的爬虫文件中,所以爬虫文件中是第一个开始工作的文件。引擎先从爬虫文件中获取到要爬取的目标网址。
2、引擎将从爬虫中获取到的网址信息交给调度器进入队列
3、调度器再根据规则将队列中的每一个网址返回给中间件
4、然后引擎经过中间件将请求信息进行包装之后交给下载器,下载器在接收到引擎交给他的request对象之后,根据request对象对目标网址发起请求并把目标网址下载下来生成一个response对象
5、下载器将response对象返回给引擎
6、然后引擎通过爬虫中间件对response对象进行处理之后把response对象交给爬虫文件
7、爬虫文件再对response对象进行处理之后提取到我们想要的数据,然后将提取到的数据交给引擎
8、引擎再将数据交给管道,管道进一步对数据进行处理、过滤、持久化到我们本地
9、如果还有进一步需要爬取的连接,那么引擎会将连接交给调度器由调度器放入队列中。
至此,一个爬取过程就完成了。
我们的scrapy数据就是循环往复的不停的进行着这一个流程帮我们不断的爬取数据。
小蜘蛛真是辛苦了。
到此,我们就把 scrapy 框架大概的学习了一遍了。
接下来要做的事情就是编写我们的爬虫程序。
